




MIRACLE CLUSTERPRO X の機能
システム障害の検知機能とフェイルオーバー機能
CLUSTERPROは、クラスターシステムを構成するハードウェア、OS、アプリケーションの状況を監視します。
障害を検知すると、業務アプリケーションに必要となる各種リソース(IPアドレス、データ、アプリケーション)を待機系サーバーに引継ぎ、ダウンタイムを最小限にとどめます。そのため、クライアントは接続先のサーバーが切り替わったことを意識せずに業務を継続します。

ダウンタイムの削減
一般にHAクラスターシステムのダウンタイムは、「障害検知の時間+フェイルオーバーの時間」となります。
- 定期的な監視作業で、障害を検知
- アプリケーションの停止、アプリケーションが使用しているDiskパーティションのアンマウント、仮想IPアドレスの開放
- アプリケーションが使用する仮想IPアドレスの取得、Diskパーティションのマウント、アプリケーションの起動
- [3]で起動したアプリケーションの監視機構の有効化
※CLUSTERPROの場合、データベースサーバーは数分、ファイルサーバー、Webサーバーなどは数十秒がダウンタイムの目安になります。
CLUSTERPRO X の種類
MIRACLE CLUSTERPRO X は、現用系ノードと待機系ノード間のデータ共有の違いにより、3種類のクラスタ構成を構築できます。
※1つのクラスターで構成可能な最大ノード数は32ノードです。
- 共有ディスクを使用:MIRACLE CLUSTERPRO X
- データミラーでデータ共有: MIRACLE CLUSTERPRO X + Replicatorオプション
- 共有ディスク型とデータミラー型を組み合わせて利用:MIRACLE CLUSTERPRO X + Replicator DRオプション
| 比較項目 | MIRACLE CLUSTERPRO X | MIRACLE CLUSTERPRO X + Replicatorオプション |
MIRACLE CLUSTERPRO X + Replicator DRオプション |
|---|---|---|---|
| データ共有方法 | 共有ディスク必須 | 共有ディスク不要 (ミラーディスク方式) |
共有ディスク必須 |
| 特徴 |
|
|
|
| 構成概念図 |  |
 |
 |
構成例
双方向スタンバイ
HAクラスターを使用すると片ノードが待機するだけでリソースがもったいないと思われがちですが、両ノードを効率的に使用できる双方向スタンバイ構成があります。これは、業務が2つ以上で、それぞれのサーバーが現用系かつ待機系である形態で運用するものです。例えば、この双方向スタンバイ構成で、WebサーバーとMailサーバーを一度にクラスター化することも可能です。


スケールアウト
CLUSTERPRO X を使用すると、業務の増加に応じて、サーバーへ追加を行いスケールアウトすることにより柔軟に対応することができます。
共有ディスクを使用している場合




データミラー型の場合
データミラーでデータ共有している場合でもスケールアウトが可能です。また、データミラー型の場合、使用済みデータ量に応じて課金されるリーズナブルな運用が可能なため、確保したデータ容量で課金されるクラウドストレージサービスに最適です。

クラウド環境におけるリーズナブルな運用方法
データミラー型の場合、使用済みデータ量に応じて課金されるリーズナブルな運用が可能なため、確保したデータ容量で課金されるクラウドサービスに最適です。

仮想環境対応
物理サーバーのクラスター化と同じように、仮想マシンのクラスター化が可能です。

障害検知範囲
ハードウェア(仮想マシン)観点
1) システムディスクのI/O障害
2) 業務データ格納用ディスクのI/O障害
3) ネットワークのI/O障害
ソフトウェア観点
4) ゲストOSのハングアップ
5) アプリケーションの停止、またはハングアップ
クラウド環境対応
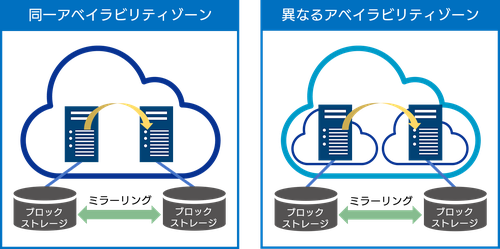
クラウド環境では、アプリケーションを含めたゲストOSより上位層の可用性確保はお客様責任となります。高可用性なシステムの構築には、複数のアベイラビリティゾーンで冗長化が求められるケースも多くあります。MIRACLE CLUSTERPRO Xを利用することで、特定ゾーンの緊急停止時も異なるアベイラビリティゾーンにて業務継続が可能となります。
Restful APIによる柔軟なアプリケーション連携
統合管理ビューア機能による管理・監視機能に加えて、Restful APIを活用してリモートから各ノードの操作や状態取得が可能です。RestfulAPIを使用し、リモートからクラスターの操作/状態取得が可能なため、他のアプリケーションと効率的で柔軟な連携が可能です。
